Polymarket Agent
We present the polyMonitor Forecast Intelligence Graph, a structured multi-agent system for generating auditable prediction-market intelligence from Polymarket data. The system combines deterministic evidence construction with model-backed specialist agents, critique, calibration, and panel generation. Its objective is not to simulate human conversation, but to produce market-level claims that are grounded in prices, fills, related markets, oracle state, and external catalysts.
Abstract
Prediction markets expose probabilistic beliefs through prices, but market interpretation requires more than a last-traded value. A useful monitoring system must jointly reason over order-book microstructure, fill activity, sibling markets, resolution criteria, oracle state, and exogenous information. We formulate polyMonitor as a graph-structured inference system. Given a market-wide evidence packet and a dashboard lens, the graph emits a calibrated panel payload, a quant snapshot, and a replayable node-level audit log. The architecture is intentionally small: deterministic nodes build the evidence state, specialist LLM agents analyze complementary uncertainty surfaces, a skeptic agent performs critique, and a writer agent converts calibrated state into dashboard views.
Problem Formulation
Let x denote a market evidence packet containing Polymarket market metadata, prices, order-book summaries, recent fills, related-market candidates, oracle state, external context, and prior forecast memory. Let l be a panel lens in {overview, special, trend}. The system learns no private market model during inference. Instead, it computes a structured mapping:
F(x, l) -> (y, q, e)where y is a dashboard-ready intelligence payload, q is a quant and data-quality snapshot, and e is an ordered event trace containing node outputs, input hashes, model identifiers, latency, token usage, tool traces, and errors. The central design constraint is auditability: every generated claim should be attributable to a bounded input packet or an explicit model-backed reasoning node.
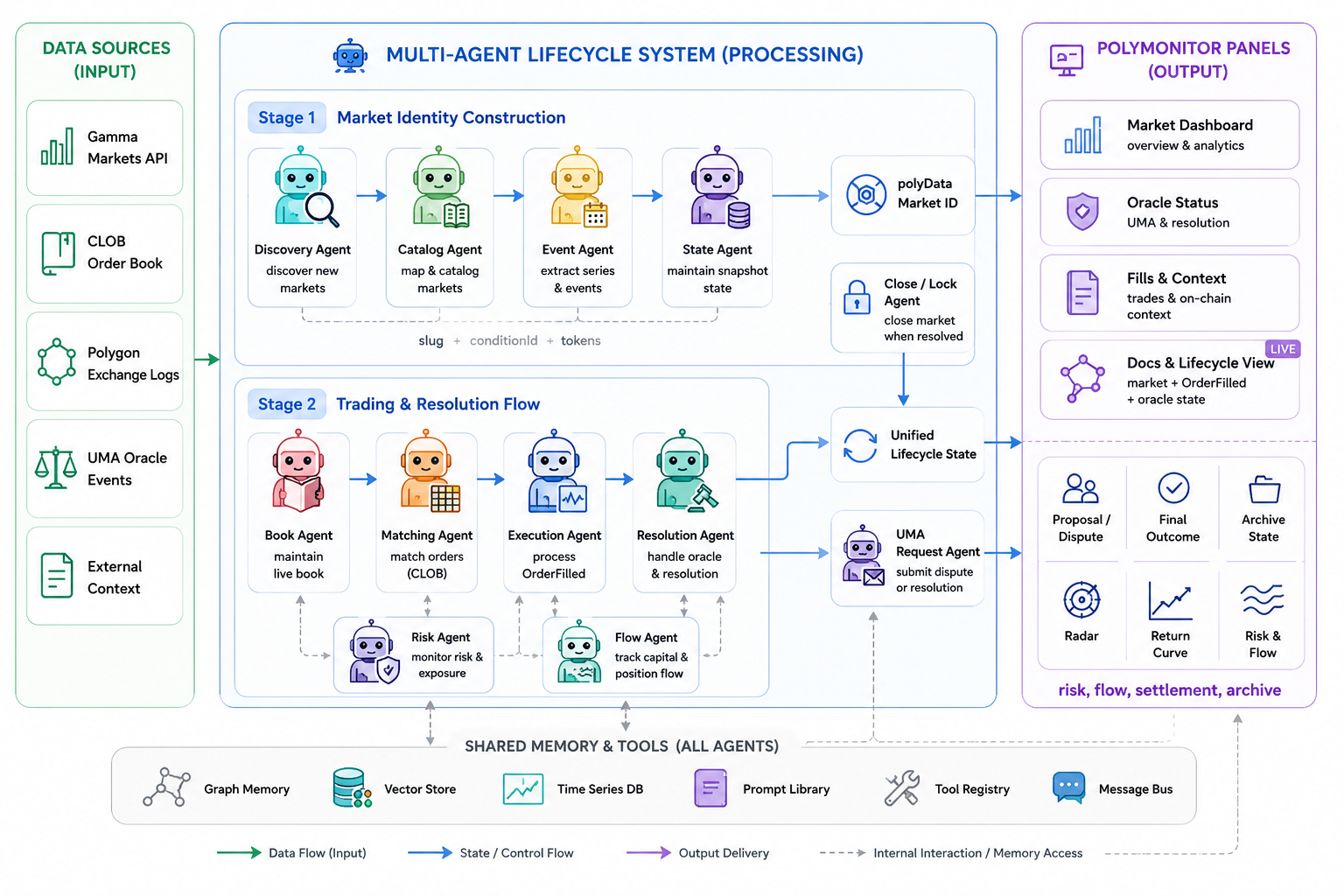
System Overview
The production graph is a directed state machine rather than an open-ended group chat. Its nodes are executed in a fixed order so that later model calls observe compact, typed state instead of an unbounded transcript. The current graph consists of deterministic state builders, three specialist model agents, a rule-based calibration node, a skeptic model agent, and a final panel writer.
evidence_builder
-> related_markets
-> quant_forecaster
-> reflexion_memory
-> microstructure
-> catalyst
-> resolution
-> calibration_agent
-> skeptic
-> panel_writerThis design follows a research-paper view of multi-agent systems: agents are introduced only when they own distinct sources of uncertainty. Microstructure, catalyst, and resolution reasoning are separated because they fail in different ways. A liquidity signal can be real while the news catalyst is stale; a catalyst can be strong while the market wording makes settlement ambiguous.
Architecture
| Node | Type | Responsibility |
|---|---|---|
| Evidence Builder | Deterministic | Constructs the initial evidence state from market candidates, groups, prices, fills, oracle snippets, external context, and search results. |
| Related Markets | Deterministic code | Links sibling markets, event-level groups, deadline ladders, adjacent outcomes, and cross-market relationships that may reveal inconsistent pricing. |
| Quant Forecaster | Deterministic code | Computes price drift, fill-tape microstructure, spread indicators, related-market scores, and data-quality warnings. |
| Reflexion Memory | Deterministic memory | Loads prior forecast episodes and summary lessons so current reasoning can be compared with historical failures and successes. |
| Microstructure Agent | LLM specialist | Analyzes named markets through implied probability, volume, trade count, fill concentration, bid/ask quality, close probabilities, and liquidity caveats. |
| Catalyst Agent | LLM specialist | Identifies external triggers, related-market catalysts, event timing, and evidence that would plausibly move market-implied probability. |
| Resolution Agent | LLM specialist | Examines market wording, deadline buckets, official-source hierarchy, oracle signals, ambiguity, and settlement risk. |
| Calibration Agent | Rule-based aggregator | Anchors confidence to market-implied prices, data warnings, related-market stress, prior Brier history, and specialist confidence. |
| Skeptic Agent | LLM critique | Challenges weak evidence, missing price-change data, stale signals, narrative overreach, and probability miscalibration. |
| Panel Writer | LLM adapter | Writes the final panel payload from evidence, specialist reports, calibration state, and memory without introducing ungrounded claims. |
Agent Prompts
Each model-backed node receives a system role, a compact JSON user packet, and a required output schema. The prompt does not ask the model to forecast from memory. It asks the model to inspect a bounded evidence state and return compact JSON containing findings, risks, watch items, confidence, and probability-adjustment notes. The specialist roles are intentionally asymmetric:
- Microstructure: price formation, fill tape, volume, trade count, liquidity concentration, and spread quality.
- Catalyst: external events, official releases, news timing, and cross-market triggers.
- Resolution: market wording, oracle conditions, settlement ambiguity, and official-source hierarchy.
- Skeptic: stale evidence, unsupported causal claims, missing data, hallucination risk, and overconfident probability shifts.
- Panel Writer: conversion from calibrated graph state into dashboard-facing English JSON.
Inference Procedure
The runtime executes the graph as a stateful inference procedure. Deterministic nodes first compress raw inputs into a graph context; model nodes then operate over that context with optional tool traces; final outputs are normalized into panel schemas and stored with replay metadata.
Algorithm 1: Forecast Intelligence Graph Inference
Input: evidence packet x, lens l
Output: panel payload y, quant snapshot q, event trace e
1: s0 <- EvidenceBuilder(x, l)
2: r <- RelatedMarkets(s0)
3: q <- QuantForecaster(s0, r)
4: m <- ReflexionMemory(s0, q, r)
5: a1 <- MicrostructureAgent(s0, r, q, m)
6: a2 <- CatalystAgent(s0, r, q, m)
7: a3 <- ResolutionAgent(s0, r, q, m)
8: c <- CalibrationAgent(q, r, m, [a1, a2, a3])
9: k <- SkepticAgent(s0, r, q, m, [a1, a2, a3], c)
10: y <- PanelWriter(s0, r, q, m, [a1, a2, a3], c, k)
11: e <- PersistNodeEvents()
12: return y, q, ePanel Lenses
The dashboard views are not independent agents. They are lenses over a shared graph run. The same evidence packet and node event trace can support overview, special, and trend views, but each lens asks the final writer to emphasize a different decision surface.
| Panel | Lens | What it should emphasize |
|---|---|---|
| Market-wide Insights | overview |
Dominant market structure, probability interpretation, top caveat, and why the board matters now. |
| Special Radar | special |
Anomalous markets, low-liquidity moves, conflicting prices, deadline ladders, and cross-market stress. |
| Trend Watch | trend |
Category rotation, attention migration, catalyst clusters, and whether isolated event interest is becoming a broader trend. |
Input Representation
The input packet is deliberately heterogeneous. Polymarket interpretation depends on market identity, trading activity, sibling markets, and settlement semantics. The graph therefore keeps the following surfaces separate rather than collapsing them into one prose context.
| Input surface | Examples | Used by |
|---|---|---|
| Price and liquidity | latestPrice, price24hAgo, volume, trade count, bid/ask, LOB spread |
Evidence Builder, Microstructure Agent, Quant Forecaster, Calibration Agent |
| Fill tape | topMarketFillTape, fill VWAP, recent fill drift, paired-fill ratio, price-source conflicts |
Microstructure Agent, Quant Forecaster, Skeptic Agent |
| Resolution context | Market title, rules, end date, oracle events, official source hierarchy, settlement state | Resolution Agent, Skeptic Agent, Panel Writer |
| External catalysts | News, official releases, match feeds, government calendars, social/media trend signals | Catalyst Agent, Skeptic Agent, Panel Writer |
| Related markets | Same-event children, handicap markets, deadline ladders, adjacent category markets | Related Markets, Quant Forecaster, Calibration Agent |
| Historical memory | Prior forecast episodes, realized resolution, price drift after prediction, Brier score, category reliability | Reflexion Memory, Calibration Agent, Skeptic Agent |
Output Schema
The system emits more than a written panel. The output is a triple: the user-facing payload, the quant evidence state, and the replayable event trace. This makes the architecture inspectable under both product and research evaluation.
{
"runId": "fig-...",
"agentArchitecture": "forecast-intelligence-graph-v2",
"agentGraph": {
"mode": "langgraph-supervisor-worker",
"runtime": "langgraph-supervisor-stategraph",
"nodes": [
"evidence_builder",
"related_markets",
"quant_forecaster",
"reflexion_memory",
"microstructure",
"catalyst",
"resolution",
"calibration_agent",
"skeptic",
"panel_writer"
],
"events": []
},
"panelPayload": {},
"usage": {
"model": "gpt-5.5",
"latencyMs": 0,
"inputChars": 0,
"outputChars": 0
}
}Evaluation Protocol
A paper-level evaluation should not score the system by prose fluency alone. The relevant question is whether the graph improves market interpretation under uncertainty while preserving calibration and auditability. We evaluate the system along four axes.
- Calibration: compare probability statements or confidence bins against realized market resolutions using Brier score, expected calibration error, and category-level reliability curves.
- Discrimination: measure whether high-confidence claims separate from low-confidence claims under subsequent price movement, resolution outcome, or analyst review.
- Faithfulness: audit whether each generated claim is supported by the evidence packet, a specialist output, a tool trace, or an explicit uncertainty statement.
- Efficiency: report latency, token usage, model calls, fallback rate, and quality changes under node ablations.
Ablations
The graph is designed to be evaluated by removing or replacing components. Useful ablations include deterministic-only output, no specialist agents, no skeptic, no reflexion memory, no related-market state, and writer-only generation. These ablations reveal whether accuracy comes from data construction, specialist reasoning, critique, or final writing.
| Ablation | Question |
|---|---|
| No specialist agents | Does deterministic evidence plus a writer perform as well as agent decomposition? |
| No skeptic | Does critique reduce unsupported causal claims and overconfident language? |
| No related markets | Does cross-market context improve detection of spread, ladder, and event-level inconsistencies? |
| No memory | Does prior forecast history improve confidence discipline and repeated-market interpretation? |
| Deterministic fallback | How much value is lost when model calls are unavailable? |
Limitations
The current system should be read as a monitoring and interpretation graph, not an autonomous trading or oracle-action agent. It does not submit orders, move liquidity, or initiate UMA disputes. It can surface resolution risk, but it does not replace legal or official settlement review. Its claims remain bounded by data freshness, source coverage, CLOB availability, model reliability, and the quality of the market metadata supplied to the graph.
Related Work
The design is closest to specialized financial and forecasting-agent systems that use structured roles, bounded context, and explicit evaluation. The useful lesson is not that more agents are always better, but that decomposition can improve interpretability when each agent owns a distinct evidence surface.
- TradingAgents: financial workflow with analysts, bull/bear researchers, trader synthesis, risk review, and final decision control.
- TradingAgents system architecture: structured reports and institutional-style coordination.
- FinCon: manager-analyst hierarchy, risk control, and verbal reinforcement for financial decision workflows.
- PROPHET: prediction-market modeling with price time series, event text semantics, and order-book microstructure.
- ForesightFlow: coordination layer, calibration, discriminative power, and cost-quality evaluation for forecasting agents.
- MASAI, SciAgents, and DrugAgent: task-specific systems that use short trajectories, explicit responsibilities, structured inputs and outputs, and domain knowledge instead of open-ended chat.
Runtime APIs
The public endpoints expose the current run artifacts needed for product display and research audit. Browser deployments access these routes through the /wm-api prefix.
| Endpoint | Returns |
|---|---|
/runtime/agent/market-wide-insights/<lens> |
Dashboard-ready panel snapshot for overview, special, or trend. |
/runtime/agent/market-wide-quant/<lens> |
Quant snapshot with price drift, fill-tape microstructure, related-market scores, and data-quality warnings. |
/runtime/agent/market-wide-events/<run_id> |
Node-level audit log for replay, debugging, latency inspection, and model-output review. |